
Os pesquisadores afirmam que o SIMA 2 pode realizar uma série de tarefas mais complexas dentro de mundos virtuais, descobrir como resolver sozinho certos desafios e conversar com seus usuários. Ele também pode melhorar enfrentando tarefas mais difíceis várias vezes e aprendendo por tentativa e erro.
“Os jogos têm sido uma força motriz por trás da pesquisa de agentes há um bom tempo”, disse Joe Marino, cientista pesquisador do Google DeepMind, em entrevista coletiva esta semana. Ele observou que mesmo uma ação simples em um jogo, como acender uma lanterna, pode envolver várias etapas: “É um conjunto realmente complexo de tarefas que você precisa resolver para progredir”.
O objetivo final é desenvolver agentes de próxima geração que sejam capazes de seguir instruções e realizar tarefas abertas em ambientes mais complexos do que um navegador da web. No longo prazo, o Google DeepMind deseja usar esses agentes para conduzir robôs do mundo real. Marino afirmou que as habilidades que o SIMA 2 aprendeu, como navegar em um ambiente, usar ferramentas e colaborar com humanos para resolver problemas, são blocos de construção essenciais para futuros companheiros robôs.
Ao contrário de trabalhos anteriores sobre agentes de jogos como AlphaZero, que derrotou um grande mestre Go em 2016, ou AlphaStar, que venceu 99,8% dos jogadores classificados de competição humana no videogame StarCraft 2 em 2019, a ideia por trás do SIMA é treinar um agente para jogar um jogo aberto sem objetivos predefinidos. Em vez disso, o agente aprende a seguir as instruções que lhe são dadas pelas pessoas.
Os humanos controlam o SIMA 2 via chat de texto, falando em voz alta ou desenhando na tela do jogo. O agente analisa os pixels de um videogame quadro a quadro e descobre quais ações ele precisa realizar para realizar suas tarefas.
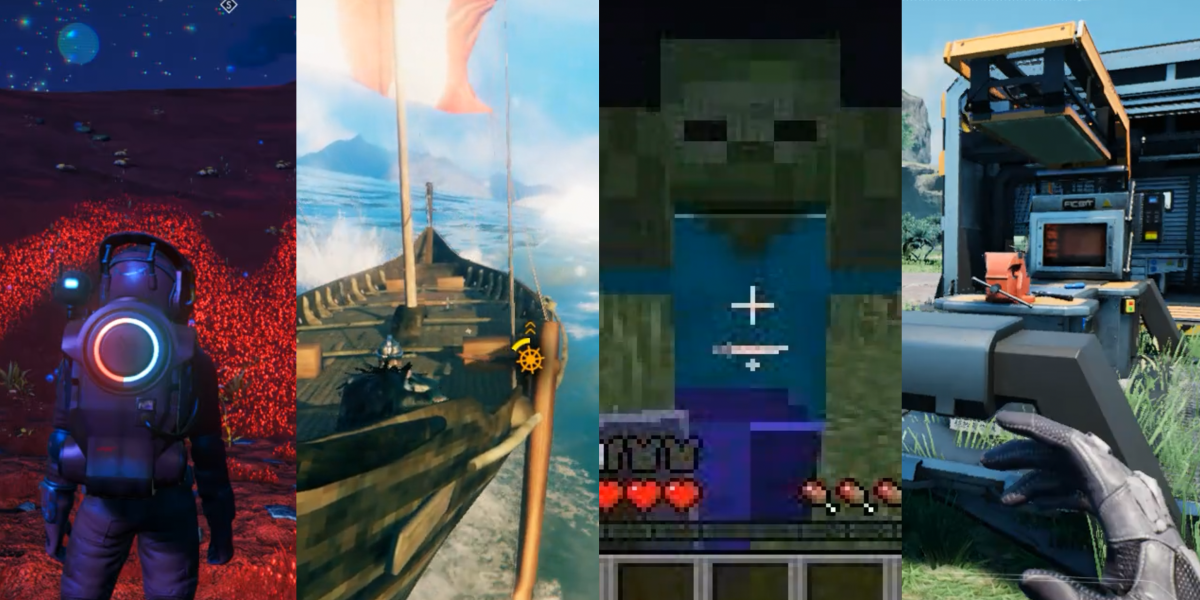
Assim como seu antecessor, SIMA 2 foi treinado em imagens de humanos jogando oito videogames comerciais, incluindo No Man’s Sky e Goat Simulator 3, bem como três mundos virtuais criados pela empresa. O agente aprendeu a combinar as entradas do teclado e do mouse com as ações.
Ligado ao Gemini, afirmam os pesquisadores, o SIMA 2 é muito melhor em seguir instruções (fazer perguntas e fornecer atualizações à medida que avança) e descobrir por si mesmo como realizar certas tarefas mais complexas.
O Google DeepMind testou o agente em ambientes nunca vistos antes. Num conjunto de experiências, os investigadores pediram ao Genie 3, a versão mais recente do modelo mundial da empresa, para produzir ambientes a partir do zero e colocaram neles o SIMA 2. Eles descobriram que o agente conseguia navegar e seguir as instruções ali.


