Documento e especificações da proposta original por @ rjl493456442: Métricas de desempenho Ethereum padronizadas – HackMD
Isso foi iniciado por Gary, quando ele implementou o registro lento de blocos no Geth. A partir daí, pensei que isso seria muito útil para muitas coisas listadas abaixo e colaborei com ele na padronização e na concretização dessa visão.
Na minha opinião, isso poderia ajudar nas reprecificações e nas faixas ScaleL1, bem como no bloatnet (meu foco atual). Embora eu ache que podemos fazer muito mais do que isso.
1. Introdução e motivação
Por que esta iniciativa existe
A filosofia multicliente da Ethereum é um ponto forte fundamental – mas cria um desafio: como comparamos o desempenho entre implementações?
Métricas de execução padronizadas resolvem isso permitindo:
- Comparação de desempenho entre clientes – Benchmarking justo e comparativo
- Monitoramento da integridade da rede — Identifique gargalos de execução antes que eles afetem o consenso
- Pesquisa de protocolo baseada em dados — Valide propostas EIP com dados reais de execução
- Detecção de anomalias — Detectar blocos incomuns (alto gás, padrões de acesso de estado complexos)
Exemplo do mundo real: análise EIP-7907
A análise EIP-7907 demonstra exatamente por que as métricas de execução padronizadas são críticas.
Usando métricas Geth, medi:
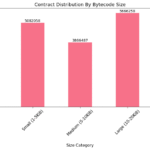
- Latência de leitura de código: 107ms a 904ms dependendo do tamanho do bytecode
- Dimensionamento de sobrecarga por chamada: 5,9µs a 49,9µs (aumento de 8,5x do menor para o maior contrato)
- Análise da execução do bloco: Isolando leituras de código, leituras de conta, execução de EVM e gravações de banco de dados
Todos esses insights ajudaram a tomar uma decisão muito mais informada. Agilizando assim muito o processo de tomada de decisão da ACD.
2. Métricas Básicas
As métricas são organizadas em categorias que abrangem o ciclo de vida de execução do bloco:
| Categoria | Caminho JSON | Descrição |
|---|---|---|
| Informações do bloco | block.* |
Número do bloco, hash, gás usado, contagem de transações |
| Tempo | timing.* |
Execução, validação, confirmação e tempo total em milissegundos |
| Taxa de transferência | throughput.* |
Taxa de processamento de Mgas/s |
| Leituras de estado | state_reads.* |
Operações de conta, armazenamento e leitura de código |
| Gravações estaduais | state_writes.* |
Mutações de conta e armazenamento |
| Cache | cache.* |
Taxas de acertos/erros para caches de conta, armazenamento e código |
Definições de métricas
| Métrica | Tipo | Descrição |
|---|---|---|
block.number |
int64 | Altura do bloco |
block.hash |
corda | Hash de bloco (prefixado 0x) |
block.gas_used |
int64 | Total de gás consumido |
block.tx_count |
int32 | Número de transações |
timing.execution_ms |
int64 | Tempo gasto na execução de transações |
timing.state_read_ms |
int64 | Tempo gasto na leitura do estado (contas, slots de armazenamento e códigos de contrato) |
timing.state_hash_ms |
int64 | Tempo gasto na reformulação do estado |
timing.total_ms |
int64 | Tempo total de processamento do bloco |
throughput.mgas_per_sec |
float64 | Produção de gás (gas_used/execution_time/1e6) |
state_reads.accounts |
int64 | Cargas de dados da conta (saldo, nonce, hash de código) |
state_reads.storage_slots |
int64 | Leituras de slot de armazenamento |
state_reads.code |
int64 | Leituras de bytecode do contrato |
state_reads.code_bytes |
int64 | Total de bytes de código lido |
state_writes.accounts |
int64 | Atualizações do estado da conta |
state_writes.storage_slots |
int64 | Gravações no slot de armazenamento |
state_writes.code |
int64 | Gravações de bytecode de contrato |
state_writes.code_bytes |
int64 | Total de bytes de gravação de código |
cache.{type}.hits |
int64 | Acessos de cache para conta/armazenamento/código |
cache.{type}.misses |
int64 | Faltas de cache (leituras de banco de dados necessárias) |
cache.{type}.hit_rate |
float64 | Porcentagem de acertos: (hits / (hits + misses)) * 100.0 |
3. Formato JSON de bloco lento
Quando a execução do bloco excede um limite configurável (padrão: 1.000 ms), os clientes geram um log JSON estruturado:
{
"level": "warn"
"msg": "Slow block"
"block": {
"number": 19234567
"hash": "0x1234...abcd"
"gas_used": 29500000
"tx_count": 234
}
"timing": {
"execution_ms": 1250
"state_read_ms": 320
"state_hash_ms": 150
"commit_ms": 75
"total_ms": 1475
}
"throughput": {
"mgas_per_sec": 23.60
}
"state_reads": {
"accounts": 5420
"storage_slots": 12340
"code": 890
"code_bytes": 456000
}
"state_writes": {
"accounts": 234
"storage_slots": 1890
}
"cache": {
"account": { "hits": 4800, "misses": 620, "hit_rate": 88.60 }
"storage": { "hits": 10200, "misses": 2140, "hit_rate": 82.68 }
"code": { "hits": 870, "misses": 20, "hit_rate": 97.75 }
}
}
Requisitos de campo
4. Status de implementação
5. Outras melhorias
Metas de médio prazo para uma análise de desempenho mais refinada:
| Melhoria | Descrição | Justificativa |
|---|---|---|
| Métricas por transação | Tempo e acesso de estado por tx individual | Identifique transações específicas que causam lentidão |
| Contagens de opcode EVM | SLOAD, SSTORE, CHAMADA, CRIAR, EXTCODECOPY | Entenda os padrões de execução, detecte vetores DoS |
| Rastreamento de acesso exclusivo | Contas exclusivas, slots de armazenamento, contratos | Medir a diversidade de acesso estadual e o tamanho do conjunto de trabalho |
| Análise de pré-compilação | Tempo por pré-compilação (ecrecover, sha256, modex) | Identifique operações criptográficas caras |
| Tempo de Merkleização | Árvore de conta versus re-hashing da árvore de armazenamento | Identifique os custos de cálculo da raiz do estado |
| Estatísticas de memória/alocação | Uso máximo de memória, alocações por bloco | Rastreie a pressão da memória para planejamento de recursos |
| Experimente estatísticas de profundidade | Profundidade média/máxima de passagem de teste | Entenda o impacto do inchaço estatal |
| Métricas de execução paralela | Utilização de threads, estatísticas de contenção | Para implementações EVM paralelas |
| Tamanho da testemunha | Tamanho dos dados de testemunha Verkle/stateless | Preparação para clientes apátridas |
| Acesso frio vs quente | Distinguir primeiro acesso versus acesso em cache | Análise de gás EIP-2929 |
Este post não quer apenas informar sobre isso, mas busca essencialmente feedback. Queremos saber o que mais seria interessante para equipes, pesquisadores e qualquer outra pessoa poder extrair/saber. Dados internos de clientes difíceis de coletar para eles, etc.
Além disso, gostaríamos de saber o que poderíamos fazer com isso, temos algumas ideias e listamos aqui mais alguns objetivos. Mas acreditamos que as pessoas terão muito mais ideias do que apenas nós.
Obrigado.
Fontesethresear