O relatório a seguir pretende ser uma coleção de dados que, esperançosamente, será um recurso que ajudará a ACD a tomar uma decisão sobre o EIP-7907.
Além disso, esperamos que isso estabeleça uma nova metodologia de respaldo de EIPs ou propostas com o máximo de dados possível, o que pode definitivamente ajudar a tomar decisões melhores e mais informadas ao definir o escopo das bifurcações.
Quero agradecer a @ rjl493456442 por seu PR adicionando métricas no Geth e por seu conselho e suporte durante a coleta de benchmark, que foi extremamente útil. E que eu gostaria de padronizar eventualmente em todos os clientes, para que possamos comparar e coletar dados facilmente para informar nossas decisões sobre reprecificação e dimensionamento.
Problema Relacionado:** EIP-7907
Data: 13/01/2026
Ambiente de referência: Geth (modo dev) com banco de dados do tamanho da rede principal (~ 24 milhões de blocos), caches internos desativados
Configuração de teste: ~18.106 operações EXTCODESIZE por bloco (todos os diferentes contratos de bytecode), ~50 milhões de gás
Hardware: WD Black SN850X NVMe (8 TB)
Sumário executivo
Este relatório analisa o desempenho do EXTCODESIZE opcode ao ler contratos de tamanhos variados de bytecode (0,5 KB a 64 KB) com o cache de código interno do Geth desativado. Isso representa o pior cenário de ataque, onde um invasor implanta milhares de contratos exclusivos para forçar leituras frias de disco.
A iteração também tem a menor sobrecarga possível. CREATE2 geração de endereços determinísticos.
Mais informações sobre isso podem ser encontradas em:
Principais conclusões
| Encontrando | Valor |
|---|---|
| Intervalo de tempo de leitura de código | 107ms – 904ms (para leituras de código de aproximadamente 18K) |
| Faixa de latência por chamada | 5,9µs – 49,9µs |
| Escala de tempo de leitura de código | Crescimento de 8,5x (0,5 KB → 64 KB) |
| Tempo de execução do bloco de 64 KB | ~1006ms |
| % de leitura de código do tempo de bloqueio | 51% (0,5 KB) → 90% (64 KB) |
| Eficiência Geth vs NVMe bruto | 24-51% |
Veredicto EIP-7907
| Tamanho | Tempo de bloqueio | % do orçamento de 1s | Veredicto |
|---|---|---|---|
| 24 KB (atual) | 535ms | 54% | Seguro |
| 32 KB | 685ms | 69% | Seguro |
| 64 KB | 1006ms | ~100% | Viável a 60M de gás |
| 128 KB ou mais | Projetado 1,5s+ | >100% | Pode ser necessário reavaliar o preço do gás. Precisamos de mais dados após BALs + ePBS |
Recomendação: Continue com 64 KB como o novo tamanho máximo do contrato. Além de 64 KB, seria necessária uma nova coleta de dados assim que as otimizações de BALs e ePBS fossem implementadas em todos os clientes.
Se fosse necessária uma reavaliação após a recolha de dados acima mencionada, tal precificação também exigiria a capacidade de avaliar o resto dos clientes, bem como olhar para o resto dos EXTCODE* códigos de operação.
1. Metodologia e configuração de benchmark
1.1 Ambiente de Teste
| Parâmetro | Valor |
|---|---|
| Versão Geth | v1.16.8-instável (com muitos hacks) |
| Banco de dados | Mainnet sincronizada (~24 milhões de blocos) |
| Obter cache | Desabilitado (força leituras de disco) |
| Tamanhos de contrato testados | 0,5, 1, 2, 5, 10, 24, 32, 64 KB |
| Operações EXTCODESIZE | ~18.106 por bloco |
| Gás por bloco | ~50 milhões |
| Contratos implantados | Mais de 18.100 contratos exclusivos por tamanho |
| Iterações por tamanho | 8 |
| Hardware | WD Black SN850X NVMe 8TB |
1.2 Desenho do Cenário de Ataque
Este parâmetro representa o ataque de pior caso contra EXTCODESIZE:
- Mais de 18.100 contratos exclusivos implantados por tamanho (força perdas de cache de código)
- Cada bloco lê bytecode de todos os contratos exclusivos exatamente uma vez
- Taxa de acerto do cache de código: <2% (efetivamente desabilitado)
- Cache de página do sistema operacional limpo entre execuções de benchmark
1.3 Linha de base do disco bruto (fio)
Para estabelecer o desempenho máximo teórico, medimos os recursos brutos do NVMe:
| Tamanho do bloco | IOPS | Taxa de transferência | Latência Média |
|---|---|---|---|
| 512B | 337 mil | 172MB/s | 95 µs |
| 1 KB | 320 mil | 328MB/s | 100 µs |
| 4 KB | 272 mil | 1,1GB/s | 117 µs |
| 24 KB | 171 mil | 4,2GB/s | 185 µs |
| 32 KB | 155 mil | 5,1GB/s | 204 µs |
| 64 KB | 85K | 5,6GB/s | 366 µs |
2. Resultados de referência
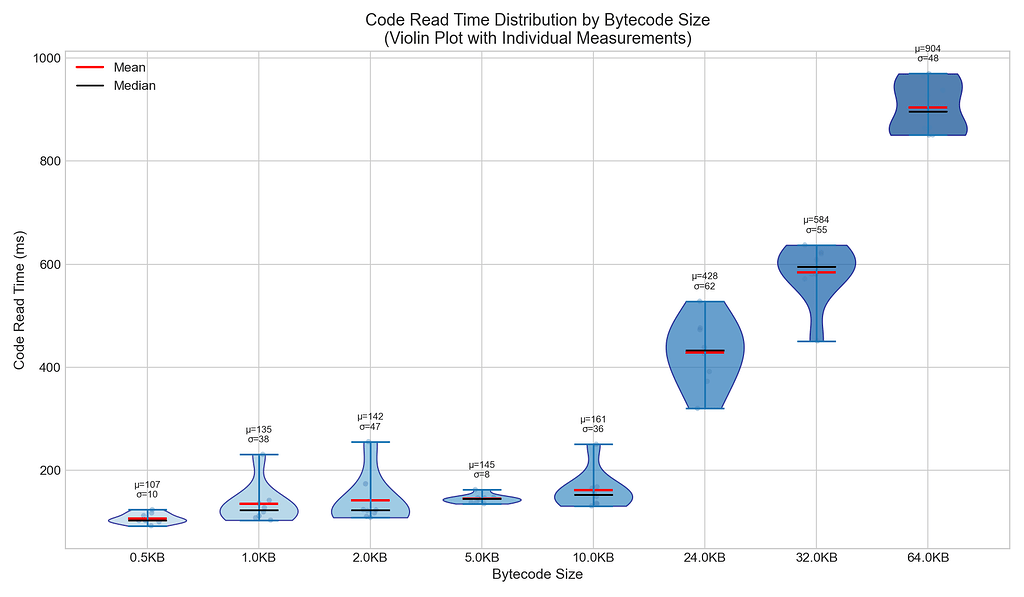
2.1 Tempo de leitura do código versus tamanho do bytecode
Descoberta principal: O tempo de leitura do código aumenta com o tamanho do bytecode quando o cache é ineficaz.
| Tamanho | Leitura de código (ms) | Crescimento versus 0,5 KB |
|---|---|---|
| 0,5 KB | 107ms | 1,0x (linha de base) |
| 1 KB | 135ms | 1,3x |
| 2 KB | 142ms | 1,3x |
| 5 KB | 145ms | 1,4x |
| 10 KB | 161ms | 1,5x |
| 24 KB | 428ms | 4,0x |
| 32 KB | 584ms | 5,5x |
| 64 KB | 904ms | 8,5x |
Visão principal: O tempo de leitura do código aumenta 8,5x à medida que o tamanho do bytecode aumenta 128x. Isso é sublinear escala (não 1:1), mas o impacto absoluto no tempo é significativo.
2.2 Bytes lidos versus tempo de leitura de código (correlação)
A forte correlação positiva (R² ≈ 0,96) confirma que o tempo de leitura do código aumenta com o total de bytes lidos quando os caches são ineficazes.
2.3 Latência por chamada
A latência por chamada aumenta com o tamanho do bytecode:
| Tamanho | Latência por chamada | Crescimento |
|---|---|---|
| 0,5 KB | 5,9 µs | 1,0x |
| 1 KB | 7,5 µs | 1,3x |
| 10 KB | 8,9 µs | 1,5x |
| 24 KB | 23,7 µs | 4,0x |
| 32 KB | 32,3 µs | 5,5x |
| 64 KB | 49,9 µs | 8,5x |
3. Detalhamento do tempo de execução
3.1 Análise de Componentes
A leitura do código torna-se o fator dominante em tamanhos de bytecode maiores:
| Tamanho | Leitura de código | Leitura da conta | Executivo de EVM | Gravação de banco de dados | Outro | Total |
|---|---|---|---|---|---|---|
| 0,5 KB | 107ms (51%) | 54ms | 34ms | 12ms | 2ms | 209ms |
| 1 KB | 135ms (57%) | 53ms | 37ms | 12ms | 1ms | 238ms |
| 10 KB | 161ms (59%) | 53ms | 40ms | 12ms | 5ms | 271ms |
| 24 KB | 428ms (80%) | 44ms | 46ms | 15ms | 2ms | 535ms |
| 32 KB | 584 ms (85%) | 38ms | 47ms | 13ms | 3ms | 685ms |
| 64 KB | 904 ms (90%) | 38ms | 51ms | 12ms | 1ms | 1006ms |
Observação: Com 64 KB, a leitura do código consome 90% do tempo de execução do bloco. Isso é dramaticamente diferente dos cenários de cache quente, onde a leitura do código é de apenas 8 a 10%.
4. Análise de orçamento de tempo de bloco (foco EIP-7907)
4.1 Tempo versus meta de orçamento
Usando uma meta de 1 segundo para execução de bloco:
| Tamanho | Tempo de bloqueio | % do orçamento de 1s | Status |
|---|---|---|---|
| 0,5 KB | 209ms | 21% | Bem abaixo do orçamento |
| 1 KB | 238ms | 24% | Bem abaixo do orçamento |
| 2 KB | 248ms | 25% | Bem abaixo do orçamento |
| 5 KB | 252ms | 25% | Bem abaixo do orçamento |
| 10 KB | 271ms | 27% | Bem abaixo do orçamento |
| 24 KB | 535ms | 54% | Abaixo do orçamento |
| 32 KB | 685ms | 69% | Abaixo do orçamento |
| 64 KB | 1006ms | ~100% | No limite |
Conclusão: Contratos de 64 KB são viáveis nas piores condições de ataque em blocos de gás de 60 milhões. O tempo de execução de aproximadamente 1 segundo está dentro do limite do orçamento, mas é aceitável. Observe que este é um limite bastante conservador, considerando que os ePBS e BALs provavelmente remodelarão o que consideramos um orçamento seguro num futuro próximo.
4.2 Taxa de processamento de gás (análise de preços incorretos)
| Tamanho | Gás Usado | Tempo de bloqueio | Mgas/s |
|---|---|---|---|
| 0,5 KB | 49,4 milhões | 209ms | 236 |
| 1 KB | 49,4 milhões | 238ms | 208 |
| 10 KB | 49,4 milhões | 271ms | 182 |
| 24 KB | 49,4 milhões | 535ms | 92 |
| 32 KB | 49,4 milhões | 685ms | 72 |
| 64 KB | 49,4 milhões | 1006ms | 49 |
Preço incorreto observado: Mesmo custo de gás, mas tempo de execução 5x diferente (236 Mgas/s → 49 Mgas/s). Isto indica que, nas piores condições, contratos maiores impõem custos desproporcionalmente mais elevados aos validadores.
Implicação para 128 KB+: Além de 64 KB, seria necessário um ajuste no modelo de gás – provavelmente um custo base mais um componente dependente do tamanho.
Observe que isso é bastante conservador. Como para “parar” a rede ou “prejudicar significativamente os validadores lentos”, a configuração necessária seria centenas de vezes maior que os 18 mil contratos únicos. O que acarreta custos enormes (não podemos reutilizá-los, pois seriam armazenados em cache após a execução do primeiro bloco).
5. Linha de base do disco bruto (eficiência Geth vs NVMe)
5.1 Comparação de eficiência
| Tamanho | Obter IOPS | IOPS NVMe brutos | Eficiência | Obter rendimento | NVMe bruto | Eficiência |
|---|---|---|---|---|---|---|
| 0,5 KB | 171 mil | 337 mil | 51% | 83MB/s | 172MB/s | 48% |
| 1 KB | 142K | 320 mil | 44% | 139MB/s | 328MB/s | 42% |
| 24 KB | 43 mil | 171 mil | 25% | 1,0GB/s | 4,2GB/s | 24% |
| 32 KB | 31K | 155 mil | 20% | 979MB/s | 5,1GB/s | 19% |
| 64 KB | 20K | 85K | 24% | 1,26GB/s | 5,6GB/s | 23% |
Observação: Geth atinge 20-51% de desempenho bruto do disco. A lacuna provavelmente se deve a:
- Sobrecarga Pebble/LevelDB (travessia de índice, filtros Bloom)
- Hashing e pesquisa de chave
- Desserialização de valor
6. Comparação com cenário de cache quente
6.1 Desempenho em cache versus desempenho sem cache
| Tamanho | Cache Quente | Cache Frio | Desacelerar |
|---|---|---|---|
| 0,5 KB | 5,3ms | 107ms | 21x |
| 1 KB | 4,4ms | 135ms | 31x |
| 2 KB | 4,5ms | 142ms | 32x |
| 5 KB | 4,6ms | 145ms | 31x |
| 10 KB | 4,7ms | 161ms | 34x |
| 24 KB | 4,8ms | 428ms | 89x |
| 32 KB | 4,9ms | 584ms | 119x |
| 64 KB | 4,9ms | 904ms | 181x |
A descoberta de “custo fixo” dos benchmarks de cache quente permanece válida para operação normal. As condições de cache frio exigem cenários de ataque extremos (mais de 18 mil contratos exclusivos).
7. Implicações para EIP-7907 e recomendações
7.1 Resumo das Constatações
- Escalas de tempo de leitura de código com tamanho sob condições de ataque (8,5x de 0,5 KB a 64 KB)
- 64 KB é viável em 60 milhões de blocos de gás – na pior das hipóteses, execução de ~1s, dentro do orçamento
- Isto representa o pior caso absoluto—18K+ contratos exclusivos são impraticáveis para implantar e manter (você precisa de um novo conjunto para cada bloco que deseja executar o ataque).
- A operação normal não é afetada—cenários de cache quente mostram custo fixo de aproximadamente 5ms
- Existe preços incorretos de gás sob ataque (variação de tempo de execução de 5x para o mesmo gás)
7.2 Recomendação EIP-7907
| Ação | Recomendação |
|---|---|
| Limite de 64 KB | Prosseguir – viável no pior caso de ataque. Não há necessidade do EIP |
| Limite de 128 KB+ | Requer nova medição com BALs + ePBS |
Parece que podemos simplesmente “manter as coisas simples” e fornecer aos desenvolvedores de contratos inteligentes uma boa atualização no limite de tamanho do código sem quaisquer alterações no protocolo além do limite de 64kB e do aumento do tamanho do código de inicialização.
Assim que tivermos BALs e ePBS em um estado mais pronto, estaremos em uma posição em que os dados nos guiarão melhor para uma boa decisão sobre reprecificação/apenas prosseguir para 256kB.
Mas parece desnecessário fazer uma reavaliação agora para algo que realmente não precisa, mesmo no pior dos casos.
7.3 Por que 64 KB é aceitável
-
Impraticabilidade do ataque: A implantação de mais de 18 mil contratos exclusivos de 64 KB requer:
- ~13 milhões de gás por implantação de contrato (base 32K + 64K × 200 gás/byte)
- Centenas de blocos apenas para configuração
- Custo contínuo significativo para manter a superfície de ataque
-
Bloqueie o tempo dentro do orçamento: Mesmo o pior caso ~1s é aceitável para blocos de gás de 60M
-
Eficácia do cache na prática: Mainnet real bloqueia contratos de reutilização; a taxa de acerto do cache de código é normalmente alta
-
Escala sublinear: O tempo de 8,5x para um crescimento de tamanho de 128x indica que a amortização ainda ajuda
Fontesethresear