Em resumo
Resumo Diário Boletim informativo
Comece cada dia com as principais notícias do momento, além de recursos originais, podcast, vídeos e muito mais.
Fontedecrypt
 Bitcoin. Image: Shutterstock/Decrypt
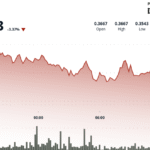
Bitcoin. Image: Shutterstock/Decrypt O preço do Bitcoin saltou acima de US$ 90.000 por moeda novamente na quarta-feira, após duas semanas difíceis que levaram muitos investidores e analistas de criptografia a apontar para o início de um mercado em baixa.
O Bitcoin atingiu quase US$ 90.334 na tarde de quarta-feira, antes de cair. Mais recentemente, seu preço foi de US$ 90.035, de acordo com a CoinGecko, após saltar mais de 3% em um período de 24 horas.
A maior moeda digital enfrentou dificuldades e despencou com outros ativos em novembro, chegando a um ponto no final da semana passada caindo para quase US$ 81.000 por moeda e apagando completamente seus ganhos de 2025.
Apenas em outubro, a criptomoeda líder estabeleceu um novo recorde de US$ 126.080. Atualmente, seu preço está quase 29% abaixo dessa marca.
Analistas que recentemente divulgaram relatórios e conversaram com Descriptografar citou o declínio do interesse dos investidores institucionais e a política incerta do Federal Reserve como algumas das razões para a queda.
O Bitcoin e outras criptomoedas têm normalmente tido um bom desempenho quando o banco central dos EUA cortou as taxas de juro, mas os observadores do mercado têm andado de um lado para o outro nas últimas semanas sobre se acham que a Fed irá instituir um terceiro corte nas taxas de juro para 2025 na sua próxima reunião em Dezembro.
Os especialistas também apontaram a diminuição da liquidez como outra razão pela qual os preços dos ativos digitais caíram. Uma quebra brutal em Outubro, que eliminou um recorde de 19 mil milhões de dólares em contratos em aberto, prejudicou gravemente os mercados.
Outras moedas e tokens digitais subiram junto com o Bitcoin na quarta-feira: Ethereum foi recentemente cotado perto de US$ 3.022 após subir 3%, enquanto Solana subiu mais alto, quase 5%, para chegar a US$ 143.
E XRP e Dogecoin obtiveram ganhos de 2% e 3%, respectivamente. Os americanos podem tirar os olhos dos mercados na quinta-feira por causa do feriado de Ação de Graças, mas a criptografia continuará sendo negociada inabalável, é claro.
Veremos se a recuperação da última semana poderá prolongar-se pelo resto do mês e até Dezembro, ou se esta será uma trégua momentânea no meio de um declínio prolongado.
Comece cada dia com as principais notícias do momento, além de recursos originais, podcast, vídeos e muito mais.
Fontedecrypt